
“Mova-se rápido e quebre as coisas” soa muito bem em uma camiseta quando você está construindo uma calculadora e o maior risco é um pequeno erro de cálculo. Considere um engenheiro civil trabalhando em pontes e túneis - ficaríamos confortáveis se eles usassem uma camiseta com o lema “conhecido que pode ser despachado”?
Não, porque queremos ter certeza de que os engenheiros a quem confiamos para construir esses sistemas críticos os projetaram para integridade estrutural, segurança dos usuários e longevidade para servir a uma geração de pessoas.
Nós, engenheiros de software, estamos no mesmo barco agora. As coisas que nossa comunidade constrói são inspiradoras e maravilhosas, e o mundo está ansioso para participar de nossa invenção. Mas com isso vem o dever de cuidar daqueles que não entendem o funcionamento interno do software ou processamento de dados, de construir sistemas que respeitem esses indivíduos e de garantir a integridade e segurança dos sistemas que oferecemos à sociedade. O termo técnico para essa consideração é “privacidade de dados”, mas na prática é o conceito de “respeito” que pode ser mais adequado. Sistemas respeitosos são aqueles em que as escolhas são apresentadas de forma transparente aos usuários, e as informações que os usuários optam por compartilhar com o sistema permanecem sob seu controle o tempo todo. Não parece pedir muito, certo? Em nosso campo, está se tornando uma aposta de mesa.
A boa notícia é que isso não significa que não podemos nos mover rapidamente. Para citar o interminável DJ Patil, podemos “nos mover com determinação e consertar as coisas”. A chave para combinar privacidade e inovação, em vez de colocá-las uma contra a outra, é incorporar privacidade ao SDLC. De forma análoga à mudança upstream da segurança do aplicativo (AppSec) no ciclo de desenvolvimento, a privacidade pertence ao início do desenvolvimento, não como uma reflexão tardia.
Conformidade vs. respeito
Há duas maneiras de olhar para o recente surgimento de interesse regulatório em nosso campo: um imposto opressor sobre a agilidade de nossa indústria (conformidade) ou uma oportunidade de construir um software melhor que respeite seus usuários em primeiro lugar. Sou otimista, então escolho o último, mas isso requer a implementação de princípios e ferramentas fundamentais de engenharia. Uma grande referência para isso são os sete princípios da Dra. Ann Cavoukian para Privacidade por Design, que são:
Proativo não reativo; preventivo não corretivo
Privacidade como configuração padrão
Privacidade embutida no design
Funcionalidade total - soma positiva, não soma zero
Segurança ponta a ponta - proteção total do ciclo de vida
Visibilidade e transparência - mantenha-o aberto
Respeito pela privacidade do usuário - mantenha-o centrado no usuário
Hoje, a privacidade de dados para a maioria das equipes de engenharia é algo resolvido depois que o software é enviado para produção. É um pouco como a segurança do aplicativo uma década atrás, em que você completaria a implementação e, em seguida, a segurança aconteceria após o fato, por meio de testes de caneta e correção de problemas conforme fossem identificados.
No entanto, nos últimos anos, o AppSec “ mudou para a esquerda ” para fazer parte do SDLC. O software bem construído é seguro antes de sair do repositório em que você estava trabalhando, e a segurança é alcançada por meio de uma mudança na mentalidade da engenharia e um conjunto de ferramentas incríveis para análise de código estático, teste de segurança de aplicativo e modelagem de ameaça que garante o código que você envia é o mais seguro possível. Os engenheiros estão cada vez mais orgulhosos de ter uma mentalidade de segurança e compreender o design defensivo e os princípios de confiança zero.
Mas, novamente, hoje a privacidade é posterior. Por exemplo, se você estiver em uma equipe em estágio inicial, itera em um MVP até encontrar o produto adequado para o mercado. Essa abordagem enxuta faz sentido para os negócios, mas assim que você tem tração - e clientes - você está coletando dados. Como você não planejou esta parte, você está expondo instantaneamente seus usuários ao risco e acumulando uma forma de dívida de planejamento de dados que é quase impossível de superar. Quanto mais bem-sucedida for sua trajetória, mais rápido será seu crescimento, mais dados você acumulará e mais agudo será o problema. Você não pode voltar atrás e desfazer a dívida, então agora você está construindo turks mecânicos não escaláveis para mitigar o risco, mas incapaz de corrigir o problema subjacente.
Os problemas de privacidade
Deixe-me apresentar alguns problemas técnicos do mundo real que isso resulta:
Problema nº 1 do mundo real: conjuntos de dados órfãos
Em grandes empresas de tecnologia, “conjuntos de dados órfãos” referem-se a conjuntos de dados que existem em sua infraestrutura que ainda estão em uso, mas não há uma compreensão clara do que está lá, de onde os dados vêm e como são usados.
Todos nós estamos familiarizados com esta história: você constrói seu primeiro produto rapidamente, então talvez sua documentação não seja perfeita ou seu modelo de dados evolua organicamente. Você encontra o sucesso e começa a crescer, então mais engenheiros se juntam à equipe. A hierarquia da equipe é bastante plana e pode girar um banco de dados e começar a trabalhar - incrível, somos a essência do Agile!
Então, você se preocupa com a disponibilidade e o dimensionamento do sistema e começa a agrupar as coisas em uma arquitetura orientada a serviços mais elegante: diferentes engenheiros selecionam peças à medida que você adiciona funcionalidade para atender à demanda do cliente. Alguns de seus primeiros engenheiros deixam a empresa, novos ingressam, o ciclo se repete e, em pouco tempo, você tem uma plataforma de mais de 500 microsserviços e centenas de bancos de dados sem quaisquer anotações ou metadados consolidados. Você não tem certeza do que serve a qual propósito e há muitas áreas cinzentas.
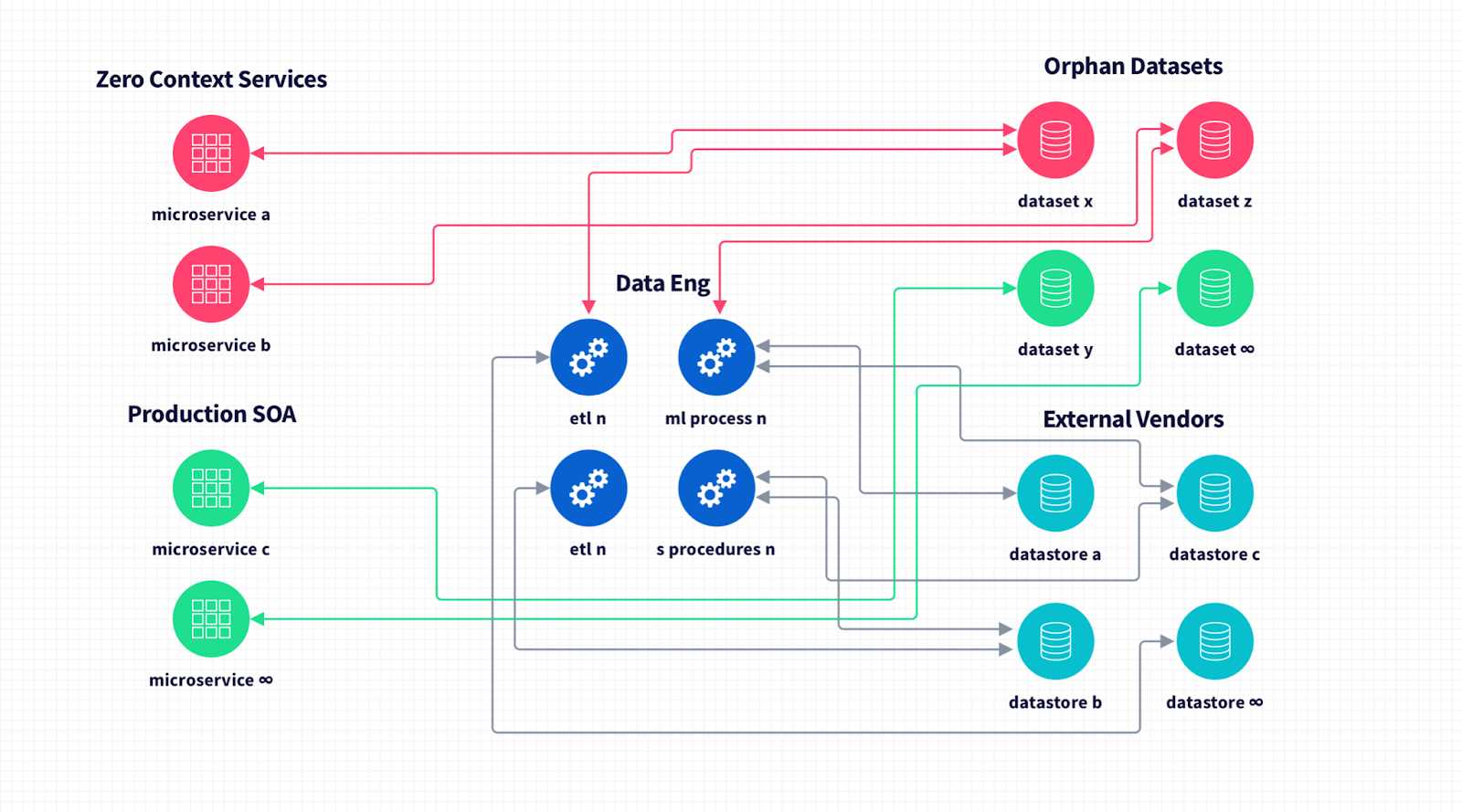
Como isso está resolvido hoje? Uma equipe de engenheiros de dados dedicados examina esses sistemas, começando com o conjunto de dados e trabalhando de forma forense na camada de serviços para entender quais dados estão sendo armazenados, o que os serviços estão fazendo e qual função de negócios está sendo executada.
E porque você não mudou suas práticas de engenharia - você ainda está enviando o código do jeito que estava - é um problema de Sísifo. Seus engenheiros de dados estão constantemente desembaraçando sistemas para tentar entender onde os dados estão e como controlá-los com segurança em nome de seus usuários.
Problema nº 2 do mundo real: fazer cumprir os direitos de um usuário
Para respeitar seus usuários, você deve respeitar seus direitos e, cada vez mais, eles são amparados por requisitos legais, como o GDPR da Europa, a CCPA da Califórnia e a LGPD do Brasil.
Esses direitos variam de acordo com o local, mas o princípio básico é que, quando um usuário do seu sistema quiser, ele pode acessar todas as informações que você tem sobre ele, atualizá-las ou excluir-se completamente. Além disso, os usuários têm direitos sobre como você tem permissão para usar seus dados. Isso cria requisitos para impedir que os dados de um usuário individual sejam usados em um processo específico em seus sistemas, caso ele discorde.
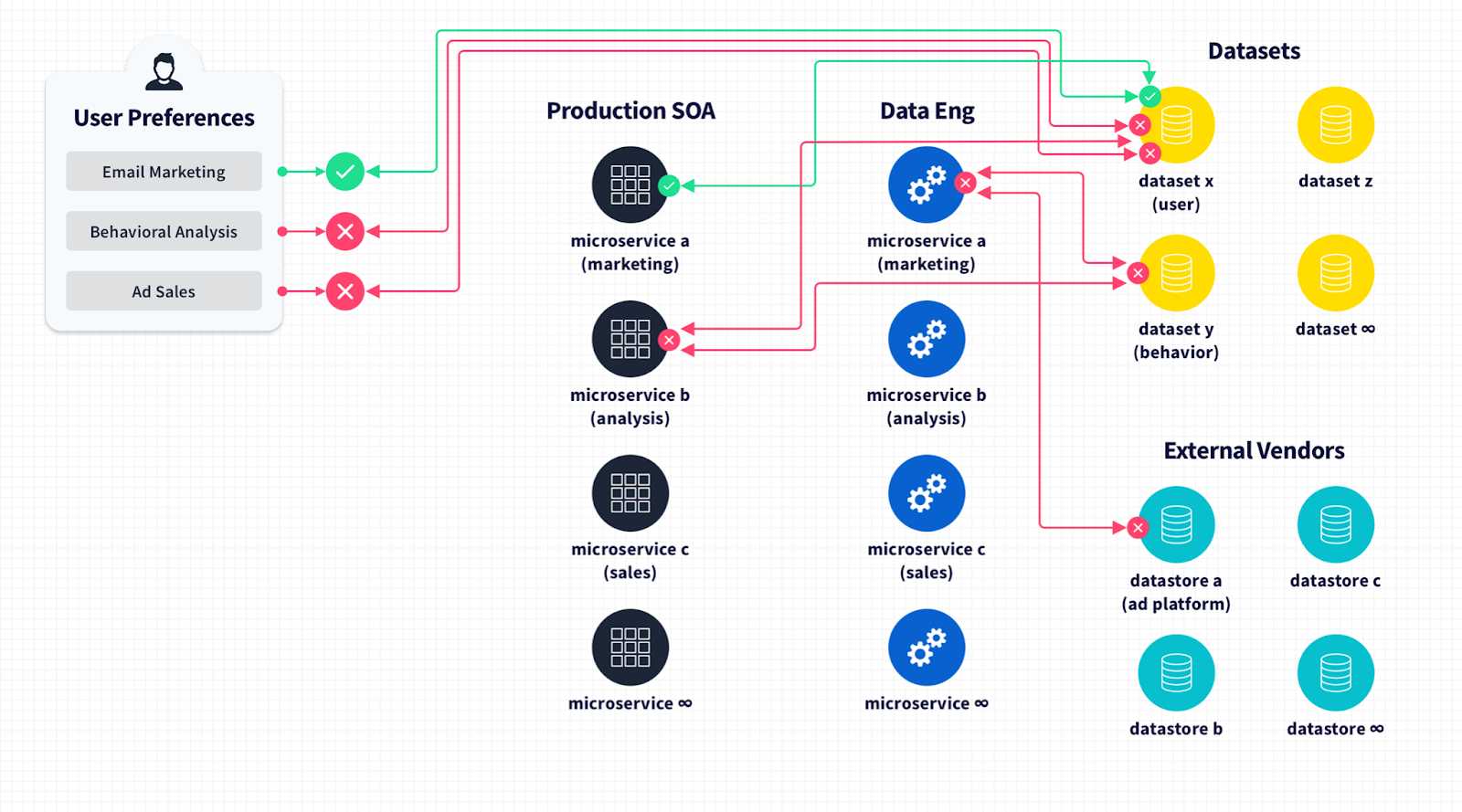
Imagine que você tenha uma arquitetura orientada a serviços realmente elegante de 400 serviços, cada um responsável por uma parte distinta da lógica de negócios. Se o usuário A em sua plataforma optar por não processar 27 das coisas que você faz, você precisa ser capaz de identificar esse indivíduo, uma única entidade em seu conjunto de dados, e impor uma restrição que pode se aplicar apenas a atributos específicos de seu conjunto de registros de entidade em um único processo - apenas uma solicitação de serviço.
Em uma visão de 10.000 pés, tudo isso é possível se você projetou sua arquitetura e modelo de dados para suportar este nível de granularidade e aplicação de política desde o início dentro do SDLC. Mas não é o que geralmente acontece.
Em uma realidade de produção, você fica com a aplicação manual de políticas, novas tabelas de políticas sendo unidas a registros de entidade em tempo de execução de maneira ad hoc para começar a aplicar restrições específicas. Ele se torna uma máquina de Rube Goldberg em que seus usuários enviam suas preferências de consentimento e caixas de seleção. Parece bom no UX, pelo menos, mas no back-end é um monte de processos manuais não escaláveis, fluxos de trabalho e runbooks para atualizar as preferências dos usuários e garantir que eles sejam excluídos de certos trabalhos de pipeline. Ele também gera relatórios para equipes jurídicas para garantir que, quando um usuário disser "não" a algo, sua preferência de consentimento seja aplicada em todo o plano de dados complexo. Para um negócio de sucesso, existe a possibilidade de que eles tenham que fazer isso milhares, até milhões de vezes.
Se esses são os sintomas, qual é a causa?
Como escrevi anteriormente, a privacidade não pode ser realmente corrigida com um bandaid depois que o sistema é construído. A causa das falhas de privacidade de dados acontece a montante no SDLC, muito antes de a maioria de nós pensar em privacidade.
Assim como a segurança do aplicativo, a origem dos problemas e o local da melhor prevenção é onde o software está sendo projetado, implementado e testado. É aqui que a instituição de decisões de design, práticas de implementação e devtools de privacidade pode mitigar riscos de privacidade como os que vemos com tanta frequência.
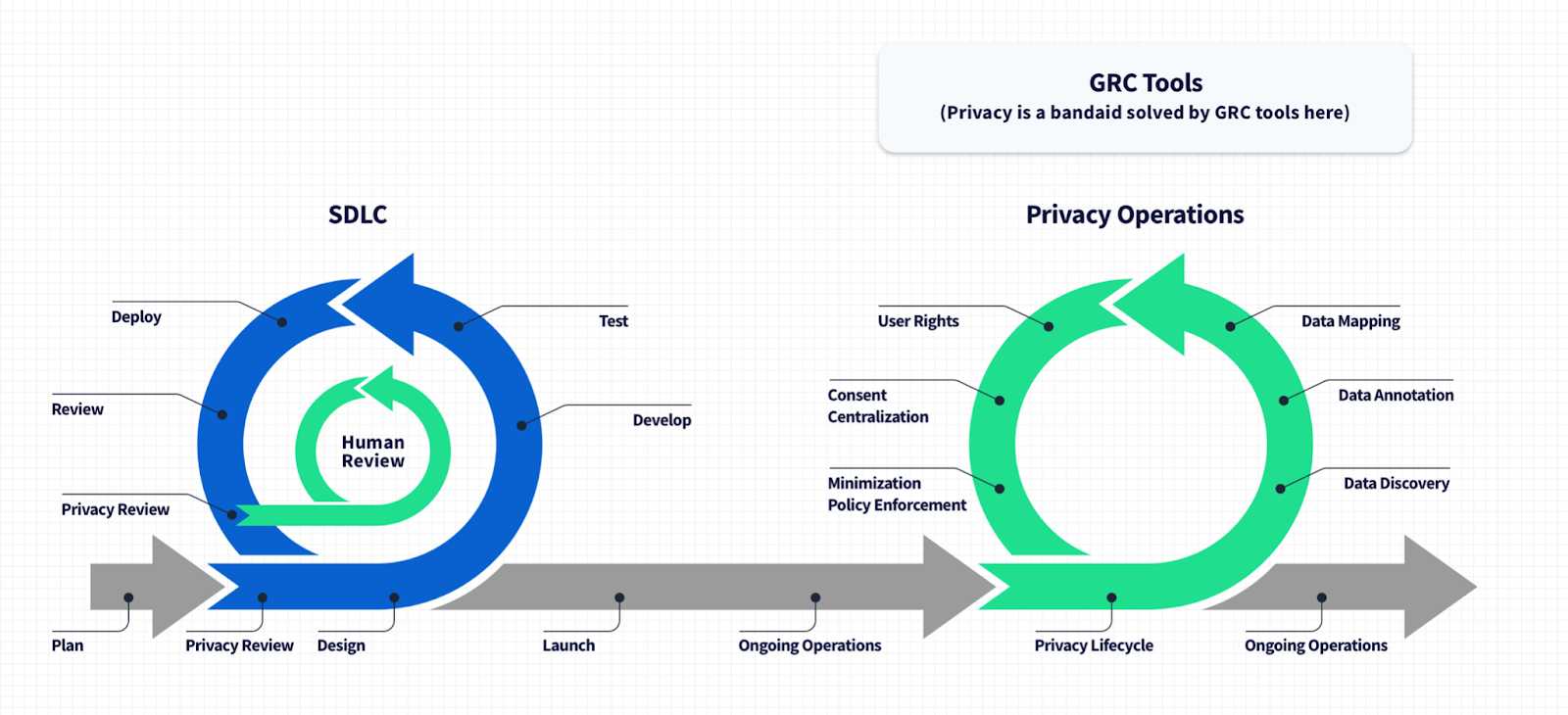
Para simplificar: se a privacidade fosse parte do processo de desenvolvimento de software, o exemplo de tentar desempacotar conjuntos de dados órfãos nunca se materializaria, porque o código mesclado em um SDLC centrado na privacidade descreverá sua finalidade, os tipos de dados que usa e seus E / S de dados para que você possa observar facilmente em todo o plano de dados. Você teria um mapa completo dos dados que passam por cada parte do código - por causa de etapas como a anotação completa no nível do código, você sabe explicitamente a substância, a fonte e o propósito dos dados em seus sistemas; cada conjunto de dados tem uma casa.
Um SDLC com privacidade embutida resulta em um sistema que respeita os direitos de seus usuários imediatamente, sem bandaids ou processos manuais. O sistema identifica fluxos de dados claramente, de forma que os esforços de mapeamento e descoberta de dados sejam redundantes; sua pilha de produtos descreve suas operações de dados imediatamente após a implantação.
Tratar a privacidade como uma reflexão tardia resulta em um grande desperdício de recursos de engenharia em operações de conformidade de dados e privacidade relacionadas à produção, o que poderia ser evitado com ferramentas melhores no pipeline de CI / CD.
Uma solução proposta para privacidade de dados
O principal problema de privacidade de nossa época é que os sistemas não são construídos para serem respeitosos de baixo para cima. Algumas das razões para isso são culturais, claro, mas algumas estão relacionadas às ferramentas à disposição das equipes de engenharia. Simplificando, até agora eles não foram adequados para a tarefa. Tenho considerado esse problema longamente e tenho algumas idéias de como ele pode ser resolvido.
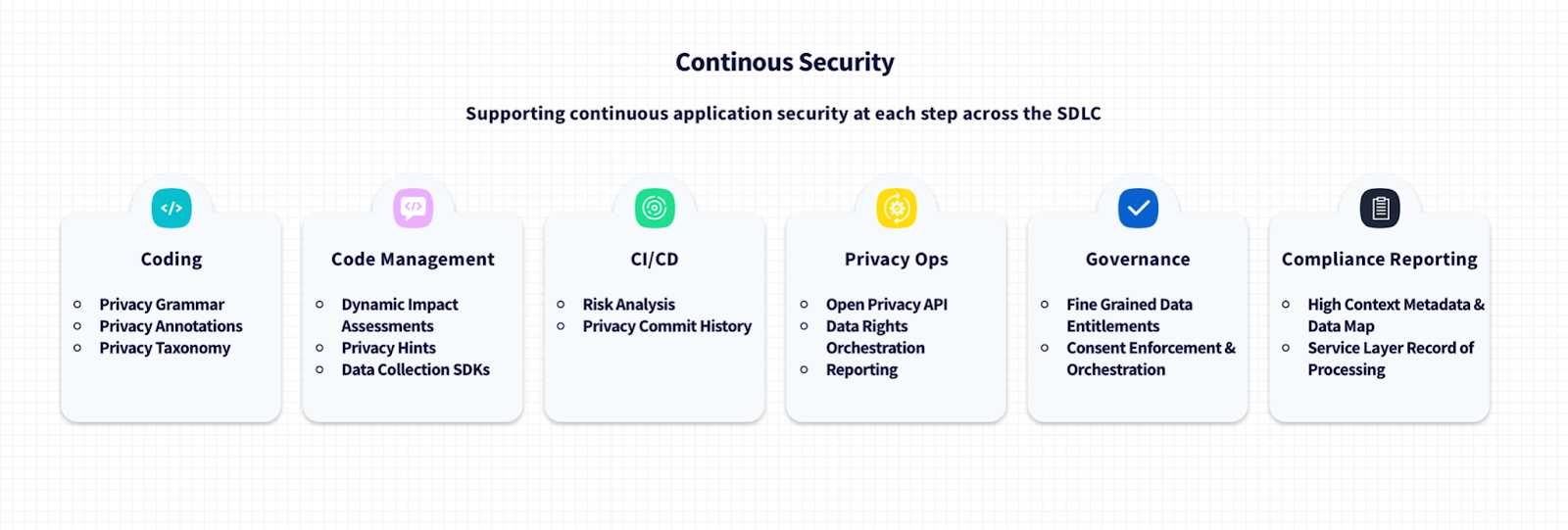
1. Ferramentas de desenvolvimento de privacidade de baixo atrito
A primeira etapa é garantir que os engenheiros tenham uma forma de 'gramática de privacidade' ou uma forma abreviada e de baixo atrito de descrever o que seu código faz e quais tipos de dados ele usa e tornar isso parte de seu editor e processo de CI. Comentários de código e documentação são um bom começo, mas uma solução completa de ferramentas pode ser lida tanto por humanos quanto por computador, integrada em fluxos de trabalho manuais e automatizados.
Ao implementar uma determinada funcionalidade em seu projeto com ferramentas integradas, os desenvolvedores podem facilmente descrever o contexto do que seu código está fazendo e em quais tipos de dados está atuando.
Além disso, da mesma forma que as ferramentas de segurança / SAST são agora um componente aceito de um processo de CI / CD bem construído, ferramentas que fornecem ganchos de CI que permitem que a gramática de privacidade e as classificações de dados sejam avaliadas em cada confirmação e MR, facilitando para aplicar sugestões aos desenvolvedores sobre como garantir que seu trabalho respeite a privacidade.
2. Avaliação de risco automatizada
Pelo menos no futuro previsível, não acredito que possamos ou devamos remover os humanos do loop. No entanto, o processo atual para a maioria das empresas cria muito atrito entre os engenheiros que tentam enviar o código e o processo de revisão manual da privacidade, enquanto também ocupa uma largura de banda valiosa.
A automação nas fases de confirmação e fusão pode preparar melhor os problemas de alto e baixo risco para a supervisão humana e remover a necessidade dos engenheiros de formulários de revisão de privacidade totalmente assíncronos. A avaliação de risco de privacidade pode ser uma parte elegante do pipeline de CI.
3. Uma taxonomia global de dados pessoais
Grande parte da privacidade começa com a compreensão dos dados que seu software usa. Um dos problemas mais comuns com privacidade saudável é concordar com um padrão para os tipos de dados em um sistema. Muitas vezes, os tipos de dados são criados pelas equipes que os utilizam, levando a uma confusão de formatos. Os requisitos legais em diferentes geografias tornam a padronização um desafio, mas isso pode ser alcançado tomando-se os padrões ISO27701 PIMS , especificamente ISO / IEC DIS 19944-1 , e construindo uma visão única da classificação de dados pessoais que pode ser modelada por cada equipe de engenharia.
Usando um único padrão para classificar os dados em um sistema, podemos simplificar a interoperabilidade dos sistemas para operações de privacidade e solicitações de direitos dos usuários, bem como obter governança uniforme entre os sistemas.
4. Um mecanismo de aplicação de política de privacidade
Hoje, a aplicação de políticas e governança requer a extensão de um sistema existente do tipo Role-Based Access Control ( RBAC ) ou Access Control List ( ACL ) para lançar sua própria solução de governança refinada, e ainda atua normalmente no conjunto de dados abstrato ou no nível do sistema.
Um modelo de política de dados de baixa granularidade deve ser projetado desde o primeiro dia para impor o acesso aos dados no nível do campo individual para cada entidade com base nas políticas gerenciadas no nível da entidade. Essa granularidade é a única maneira de garantir que os direitos de privacidade possam ser verdadeiramente aplicáveis. Para que isso seja possível, no entanto, é necessária uma escala de interoperabilidade, portanto, a integração com um modelo de aplicação de política padrão como o Open Policy Agent é uma etapa fundamental.
5. Faça do consentimento parte da validação em frameworks front-end
Hoje, o consentimento é geralmente tratado por meio de banners de cookies ou sinalizadores individuais definidos em tempo de execução em um fluxo de formulário. O consentimento pode e deve fazer parte do módulo de validação de todas as estruturas front-end. Se já sabemos em tempo de execução quais dados estão sendo coletados (porque estamos validando para isso), esses mesmos validadores podem ser usados para verificar o contexto. Ferramentas como o modelo de política de dados refinado descrito acima permitiriam a qualquer engenheiro estender essas validações para verificar de maneira sensata o tipo de dados e o consentimento.
Já usamos validação contra tipos de campo para gerar verificações de lógica de negócios para tipo de dados, estrutura, etc. Isso deve ser estendido para garantir que os rótulos de campo determinem se o consentimento deve ser coletado automaticamente e fornecer um serviço central de rastreamento de consentimento no tempo de execução do aplicativo para que o usuário consinta é unificado em todo o uso do aplicativo. Essas etapas tornam mais difícil para os sistemas falharem acidentalmente em registrar as opções de consentimento ou comunicar os direitos de um usuário.
6. Um registro de privacidade imutável
Cada aplicativo deve manter um registro hash de ações relacionadas à privacidade. Tal registro permitiria aos engenheiros rastrear de forma confiável os direitos do usuário e as atividades de privacidade através do aplicativo e do ciclo de vida do usuário e demonstrar as decisões tomadas no pipeline de privacidade do CI.
Confiança através da transparência
Transparência e privacidade podem parecer companheiros estranhos, mas na verdade estão intimamente ligados. Pense no sexto princípio do Dr. Cavoukian de privacidade desde o design: visibilidade e transparência. Um compromisso com a construção de sistemas confiáveis se aplica às próprias ferramentas de construção desses sistemas. Então, cada engenheiro, mesmo sem um treinamento profundo, pode fazer um trabalho melhor de incorporar privacidade em seu código e, ao mesmo tempo, reduzir o atrito entre as equipes de engenharia e jurídica.
Como engenheiros de software, construímos os sistemas nos quais bilhões de pessoas dependem para suas finanças, segurança, saúde e bem-estar. Nossas ferramentas e processos devem refletir a seriedade de nossa responsabilidade em respeitar os dados dos usuários. Uma abordagem post-hoc para privacidade é trabalhosa e arriscada. É fundamentalmente reativo, incapaz de escalar com o rápido crescimento dos sistemas que alimentam nosso mundo.
Ao equipar os engenheiros com as ferramentas para implementar a privacidade desde o projeto dentro do SDLC, construímos sistemas melhores, mais seguros e mais respeitosos. Em um nível operacional, reduzimos a dor de corrigir problemas na produção, permitindo que nossas equipes se concentrem na inovação em vez de lutar para obter conformidade após o fato. Em um nível cultural, oferecemos sistemas que realmente conquistam a confiança dos usuários, que são os únicos sistemas que valem a pena construir na década de 2020.
Por anos, os engenheiros deixaram a AppSec como uma reflexão tardia. Hoje, é quase impossível pensar em um SDLC típico sem o AppSec embutido nele. Podemos e devemos seguir uma abordagem paralela com a privacidade.








