
Então ... cache. O que é isso? É uma maneira de obter uma recompensa rápida, não recalculando ou buscando coisas repetidamente, resultando em ganhos de desempenho e custo. É mesmo daí que vem o nome, é uma forma abreviada de "ca-ching!" som de caixa registradora da idade das trevas de 2014, quando a moeda física ainda era uma coisa, antes do Apple Pay. Agora sou pai, lide com isso.
Digamos que precisamos chamar uma API ou consultar um servidor de banco de dados ou apenas pegar um bilhão de números (o Google diz que é uma palavra real , eu verifiquei) e somá- los. Esses são todos relativamente louco caro. Portanto, armazenamos o resultado em cache - o mantemos à mão para reutilização.
Por que fazemos cache?
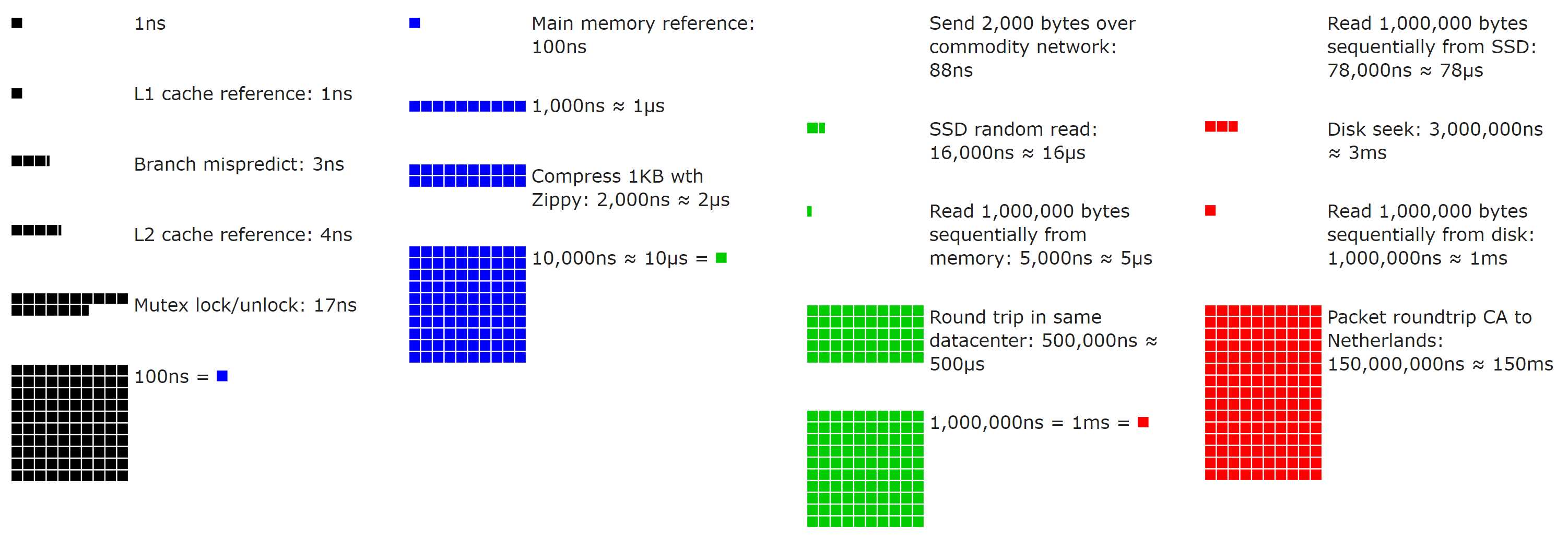
Eu acho que é importante discutir aqui o quão caro algumas das coisas acima são. Existem várias camadas de armazenamento em cache em seu computador moderno. Como um exemplo concreto, vamos usar um de nossos servidores web, que atualmente hospeda um par de CPUs Intel Xeon E5-2960 v3 e DIMMs de 2133 MHz. O acesso ao cache é um recurso de "quantos ciclos" de um processador, portanto, sabendo que sempre rodamos a 3,06 GHz (modo de potência de desempenho), podemos derivar as latências ( referência da arquitetura Intel aqui - esses processadores estão na geração Haswell):
L1 (por núcleo): 4 ciclos ou latência de ~ 1,3 ns - 12x 32 KB + 32 KB
L2 (por núcleo): 12 ciclos ou latência de ~ 3,92 ns - 12x 256 KB
L3 (compartilhado): 34 ciclos ou latência de ~ 11.11ns - 30 MB
Memória do sistema: latência de ~ 100ns - 8x 8 GB
Cada camada de cache pode armazenar mais, mas está mais distante. É uma troca no design do processador com equilíbrios em jogo. Por exemplo, mais memória por núcleo significa (quase certamente) em média colocá-la mais longe do núcleo no chip, e isso tem custos de latência, custos de oportunidade e consumo de energia. A distância que os elétrons precisam percorrer tem um impacto substancial nessa escala; lembre-se de que a distância é multiplicada por bilhões a cada segundo.
E não entrei na latência de disco acima porque raramente tocamos no disco. Por quê? Bem, acho que para explicar que precisamos ... olhar para os discos. Ooooooooh discos brilhantes! Mas, por favor, não toque neles depois de andar por aí de meias. No Avance Network, qualquer produção que não seja um servidor de backup ou registro está em SSDs. O armazenamento local geralmente se enquadra em alguns níveis para nós:
NVMe SSD: ~ 120μs ( fonte )
SATA ou SAS SSD: ~ 400–600μs ( fonte )
HDD rotacional: 2–6ms ( fonte )
Esses números estão mudando o tempo todo, então não se concentre muito em números exatos. O que estamos tentando avaliar é a magnitude da diferença dessas camadas de armazenamento. Vamos analisar a lista (assumindo o limite inferior de cada um, esses são os números do melhor caso):
L1: 1,3 ns
L2: 3,92ns ( 3x mais lento )
L3: 11,11 ns ( 8,5x mais lento )
RAM DDR4: 100ns ( 77x mais lento )
NVMe SSD: 120.000ns ( 92.307x mais lento )
SATA / SAS SSD: 400.000 ns ( 307.692x mais lento )
HDD rotacional: 2–6ms ( 1.538.461x mais lento )
Login do Microsoft Live: 12 redirecionamentos e 5s ( 3.846.153.846x mais lento , aproximadamente)
Se os números não são sua praia, aqui está uma visualização de código aberto bacana (use o controle deslizante!) Por Colin Scott (você pode até ver como eles evoluíram ao longo do tempo - realmente bacana):
Com esses números de desempenho e um senso de escala em mente, vamos adicionar alguns números importantes todos os dias. Digamos que nossa fonte de dados esteja X, onde o que X está não importa. Pode ser SQL, ou um microsserviço, ou um macrosserviço, ou um serviço do teclado esquerdo, ou Redis, ou um arquivo em disco, etc. A chave aqui é que estamos comparando o desempenho dessa fonte com o da RAM. Digamos que nossa fonte pegue ...
100ns (da RAM - rápido!)
1ms (10.000x mais lento)
100ms (100.000x mais lento)
1s (1.000.000x mais lento)
Não acho que precisamos ir mais longe para ilustrar o ponto: mesmo as coisas que levam apenas 1 milissegundo são muito, muito mais lentas do que a RAM local . Lembre-se: milissegundo, microssegundo, nanossegundo - apenas no caso de alguém esquecer que 1000ns! = 1ms como eu às vezes faço ...
Mas nem todo cache é local. Por exemplo, usamos Redis para armazenamento em cache compartilhado por trás de nossa camada da web ( que abordaremos em breve) Digamos que estamos cruzando nossa rede para obtê-lo. Para nós é uma viagem de ida e volta de 0,17ms e você também precisa enviar alguns dados. Para coisas pequenas (nosso usual), isso vai ser em torno de 0,2–0,5 ms no total. Ainda 2.000–5.000x mais lento do que a RAM local, mas também muito mais rápido do que a maioria das fontes. Lembre-se de que esses números são porque estamos em uma pequena LAN local. A latência da nuvem geralmente será maior, então meça para ver sua latência.
Quando obtemos os dados, talvez também queiramos massagear de alguma forma. Provavelmente sueco. Talvez precisemos de totais, talvez precisemos filtrar, talvez precisemos codificá-los, talvez precisemos modificá-los aleatoriamente apenas para enganar você. Foi um teste para ver se você ainda está lendo. Você passou! Seja qual for o motivo, a semelhança é geralmente o que queremos fazer x uma vez , e não cada vez que o servimos .
Às vezes, economizamos latência e às vezes economizamos CPU. Geralmente, um ou ambos são o motivo pelo qual o cache é introduzido. Agora vamos cobrir o outro lado ...
Por que não armazenaríamos em cache?
Para todos que odeiam cache, esta seção é para você! Sim, estou totalmente jogando dos dois lados.
Dado o exposto acima e quão drásticas são as vitórias, por que não armazenaríamos algo em cache? Bem, porque cada decisão tem vantagens e desvantagens . Cada. Solteiro. 1. Pode ser tão simples quanto tempo gasto ou custo de oportunidade, mas ainda há uma compensação.
Quando se trata de cache, adicionar um cache acarreta alguns custos:
Purgar valores se e quando necessário (invalidação de cache - abordaremos isso em alguns instantes )
Memória usada pelo cache
Latência de acesso ao cache (ponderada em relação ao acesso à fonte)
Tempo adicional e sobrecarga mental gastos depurando algo mais complicado
Sempre que surge um candidato para armazenamento em cache (geralmente com um novo recurso), precisamos avaliar essas coisas ... e isso nem sempre é uma coisa fácil de fazer. Embora o cache seja uma ciência exata, bem como a astrologia, ainda é complicado.
Aqui no Avance Network, nossa arquitetura tem um tema abrangente: mantê-lo o mais simples possível. Simples é fácil de avaliar, raciocinar, depurar e alterar, se necessário. Apenas torne mais complicado se e quando precisar ser mais complicado. Isso inclui cache. Apenas armazene em cache se for necessário. Ele adiciona mais trabalho e mais chances de bugs , então, a menos que seja necessário: não faça isso. Pelo menos ainda não.
Vamos começar fazendo algumas perguntas.
É muito mais rápido acessar o cache?
O que estamos salvando?
Vale a pena o armazenamento?
Vale a pena limpar o referido armazenamento (por exemplo, coleta de lixo)?
Ele irá para a pilha de objetos grandes imediatamente?
Com que frequência temos que invalidá-lo?
Quantos acessos por entrada de cache achamos que obteremos?
Ele vai interagir com outras coisas que complicam a invalidação?
Quantas variantes haverá?
Precisamos alocar apenas para calcular a chave?
É um cache local ou remoto?
É compartilhado entre os usuários?
É compartilhado entre sites?
Ele depende do emaranhamento quântico ou depurá-lo apenas faz você pensar assim?
Qual é a cor do cache?
Todas essas são questões que surgem e afetam as decisões de armazenamento em cache. Vou tentar cobri-los por meio deste post.
Camadas de Cache no Avance Network
Temos nossos próprios caches “L1” / ”L2” aqui no Avance Network, mas evitarei referir-me a eles dessa forma para evitar confusão com os caches de CPU mencionados acima. O que temos são vários tipos de cache. Vamos primeiro cobrir rapidamente os caches locais e de memória aqui para a terminologia, antes de nos aprofundarmos nos bits comuns usados por eles:
“Global Cache” : In-memory cache (global, por servidor web e apoiado por Redis em caso de falha)
Normalmente, coisas como a contagem da barra superior de um usuário, compartilhada pela rede
Isso atinge a memória local (keyspace compartilhado) e, em seguida, Redis (keyspace compartilhado, usando o banco de dados 0 do Redis)
“Cache do site” : cache na memória (por site, por servidor web e apoiado por Redis na falta)
Normalmente, coisas como listas de perguntas ou listas de usuários que são por site
Isso atinge a memória local (keyspace por site, usando prefixação) e, em seguida, Redis (keyspace por site, usando bancos de dados Redis)
“Cache Local” : cache de memória (por site, por servidor web, apoiado por nada )
Normalmente coisas que são baratas de buscar, mas enormes para transmitir e o salto do Redis não vale a pena
Isso atinge apenas a memória local (keyspace por site, usando prefixação)
O que queremos dizer com “por site”? O Avance Network e a rede de sites é uma arquitetura multilocatário . Avance Network é apenas um entre muitas centenas de sites . Isso significa que um processo no servidor da web hospeda todos os sites, portanto, precisamos dividir o cache quando necessário. E teremos que eliminá-lo ( veremos como isso funciona também ).
Redis
Antes de discutirmos como os servidores e o cache compartilhado funcionam, vamos abordar rapidamente sobre o que os bits compartilhados são construídos: Redis. Então, o que é Redis ? É um armazenamento de dados de chave / valor de código aberto com muitas estruturas de dados úteis, mecanismos adicionais de publicação / assinante e estabilidade sólida.
Por que Redis e não something else? Bem, porque funciona. E funciona bem. Pareceu uma boa ideia quando precisávamos de um cache compartilhado. Tem sido incrivelmente sólido como uma rocha. Não esperamos por isso - é incrivelmente rápido. Nós sabemos como funciona. Estamos muito familiarizados com isso. Sabemos como monitorá-lo. Nós sabemos como soletrar. Mantemos uma das bibliotecas de código aberto mais usadas para ele. Podemos ajustar essa biblioteca se precisarmos.
É uma peça de infraestrutura que nós apenas não se preocupe . Basicamente, consideramos isso garantido (embora ainda tenhamos uma configuração de HA de réplicas - não somos completamente malucos). Ao fazer escolhas de infraestrutura, você não muda as coisas apenas pelo valor possível percebido. Mudar exige esforço, tempo e envolve riscos. Se o que você tem funciona bem e faz o que você precisa, por que investir tempo e esforço e arriscar? Bem ... você não. Existem milhares de coisas melhores que você pode fazer com seu tempo. Como debater qual servidor de cache é o melhor!
Temos algumas instâncias do Redis para separar as preocupações dos aplicativos (mas no mesmo conjunto de servidores). Aqui está um exemplo de como é:

Para os curiosos, algumas estatísticas rápidas da última terça-feira (30/07/2019). Isso ocorre em todas as instâncias nas caixas principais (porque as dividimos para organização, não desempenho ... uma instância poderia lidar com tudo o que fazemos com bastante facilidade):
Nossos servidores físicos Redis têm 256 GB de memória, mas menos de 96 GB usados.
1.586.553.473 comandos processados por dia (3.726.580.897 comandos e 86.982 por segundo de pico em todas as instâncias - devido às réplicas)
Média de 2,01% de utilização da CPU (3,04% de pico) para todo o servidor (1%, mesmo para a instância mais ativa)
124.415.398 chaves ativas (422.818.481 incluindo réplicas)
Esses números se referem a 308.065.226 hits HTTP (64.717.337 dos quais eram páginas de perguntas)
Observação: nenhum deles é limitado pelo Redis - estamos longe de quaisquer limites. É apenas quanta atividade existe em nossas instâncias.
Também há razões não cache para usarmos o Redis, a saber: também usamos o mecanismo pub / sub para nossos websockets que fornecem atualizações em tempo real sobre pontuações, rep, etc. O Redis 5.0 adicionou Streams que é um ajuste perfeito para nossos websockets e nós ' Provavelmente migrarei para eles quando algumas outras peças de infraestrutura estiverem no lugar (principalmente limitado pela versão do Avance Network Enterprise no momento).
O Avance Network é uma comunidade fácil de usar que fornece segurança de primeira e não requer muito conhecimento técnico. Com uma conta, você pode proteger sua comunicação e seus dispositivos. O Avance Network não mantém registros de seus dados; portanto, você pode ter certeza de que tudo o que sai do seu dispositivo chega ao outro lado sem inspeção.








