
Para os casos apresentados neste post, a vetorização melhorou o desempenho por um fator de 3 a 12.
Introdução
Muitos desenvolvedores escrevem softwares sensíveis ao desempenho. Afinal, essa é uma das principais razões pelas quais ainda escolhemos a linguagem C ou C++ nos dias de hoje.
Todos os processadores modernos são na verdade vetores sob o capô. Ao contrário dos processadores escalares, que processam dados individualmente, os modernos processadores vetores processam matrizes unidimensionais de dados. Se você quiser maximizar o desempenho, você precisa escrever código adaptado a esses vetores.
Toda vez que você escreve float s = a + b; você está deixando um monte de desempenho sobre a mesa. O processador poderia ter adicionado quatro números flutuantes a outros quatro números, ou até oito números a outros oito números se esse processador suportaSSE AVX. Da mesma forma, quando você escreve int i = j + k; para adicionar 2 números inteiros, você poderia ter adicionado quatro ou oito números em vez disso, com instruções SSE2 ou AVX2 correspondentes.
Designers de idiomas, desenvolvedores de compiladores e outras pessoas inteligentes têm tentado por muitos anos compilar código escalar em instruções vetoriais de uma maneira que aproveitaria o potencial de desempenho. Até agora, nenhum deles conseguiu completamente, e não estou convencido de que seja possível.
Uma abordagem para alavancar o hardware vetorial são os intrínsecos SIMD, disponíveis em todos os compiladores C ou C++modernos. SIMD significa "Instrução única, múltiplos dados". As instruções simd estão disponíveis em muitas plataformas, há uma grande chance de seu smartphone ter também, através da extensão de arquitetura ARM NEON. Este artigo se concentra em PCs e servidores rodando em processadores AMD64 modernos.
Mesmo com o foco na plataforma AMD64, o tema é muito amplo para um único post no blog. As instruções modernas do SIMD foram introduzidas aos processadores Pentium com o lançamento do Pentium 3 em 1999 (esse conjunto de instruções é SSE, hoje em dia é às vezes chamado de SSE 1), mais deles foram adicionados desde então. Para uma introdução mais aprofundada, você pode ler meu outro artigo sobre o assunto. Ao contrário deste post no blog, que não se tem problemas práticos nem benchmarks, em vez disso, tenta fornecer uma visão geral do que está disponível.
O que são intrínsecos?
Para um programador, os intrínsecos se parecem com funções regulares da biblioteca; você inclui o cabeçalho relevante, e você pode usar o intrínseco. Para adicionar quatro números flutuantes a outros quatro números, use o _mm_add_ps intrínseco em seu código. No cabeçalho fornecido pelo compilador declarando que intrínseco, xmmintrin.h, você encontrará esta declaração (Supondo que esteja usando o compilador VC+++. No GCC você verá algo diferente, que fornece a mesma API para um usuário.):
extern __m128 _mm_add_ps( __m128 _A, __m128 _B );
Mas ao contrário das funções da biblioteca, os intrínsecos são implementados diretamente em compiladores. O _mm_add_ps SSE intrínseco tipicamente1 compila em uma única instrução, addps. Pelo tempo que a CPU leva para chamar uma função de biblioteca, ela pode ter completado uma dúzia dessas instruções.
1(Essa instrução pode buscar um dos argumentos da memória, mas não ambos. Se você chamá-lo de uma forma para que o compilador tenha que carregar ambos os argumentos da memória, como este __m128 sum = _mm_add_ps( *p1, *p2 ); o compilador emitirá duas instruções: a primeira a carregar um argumento da memória em um registro, a segunda a adicionar os quatro valores.)
O __m128 tipo de dados incorporado é um vetor de quatro números de pontos flutuantes; 32 bits cada, 128 bits no total. As CPUs possuem registros amplos para esse tipo de dados, 128 bits por registro. Desde que o AVX foi introduzido em 2011, nos atuais processadores de PC esses registros têm 256 bits de largura, cada um deles pode caber oito valores de flutuação, quatro valores flutuantes de dupla precisão ou um grande número de inteiros, dependendo do seu tamanho.
O código fonte que contém quantidades suficientes de intrínsecas vetoriais ou incorpora seus equivalentes de montagem é chamado de código vetorial manualmente. Compiladores e bibliotecas modernos já implementam um monte de coisas com eles usando intrínsecos, montagem ou uma combinação dos dois. Por exemplo, algumas implementações das rotinas de biblioteca memset, memcpyou memmove padrão C usam instruções SSE2 para melhor throughput. No entanto, fora de áreas de nicho como computação de alto desempenho, desenvolvimento de jogos ou desenvolvimento de compiladores, mesmo programadores C e C++ muito experientes não estão familiarizados com os intrínsecos SIMD.
Para ajudar a demonstrar, vou apresentar três problemas práticos e discutir como o SIMD ajudou.
Processamento de imagem: escala de cinza
Suponha que precisamos escrever uma função que converta a imagem RGB em escala de cinza. Alguém fez essa mesma pergunta recentemente..
Muitas aplicações práticas precisam de código como este. Por exemplo, quando você compacta dados de imagem bruta para JPEG ou dados de vídeo para H.264 ou H.265, o primeiro passo da compressão é bastante semelhante. Especificamente, os compressores convertem pixels RGB em espaço de cor YUV. O espaço de cores exato é definido nas especificações desses formatos — para vídeo, muitas vezes é ITU-R BT.709 nos dias de hoje Ver a seção 3, "Formato de sinal" dessa especificação.
Comparação de desempenho
Implementei algumas versões, vetoriamente vetoriamente e não as testei com imagens aleatórias. Mydesktop tem um AMD Ryzen 5 3600 conectado, meu laptop tem um Intel i3-6157U soldado. A coluna WSL tem resultados do mesmo desktop, mas para um binário Linux construído com GCC 7.4. As três colunas mais à direita da tabela contêm tempo em milissegundos (melhor de cinco corridas), para uma imagem de 3840×2160 pixels.
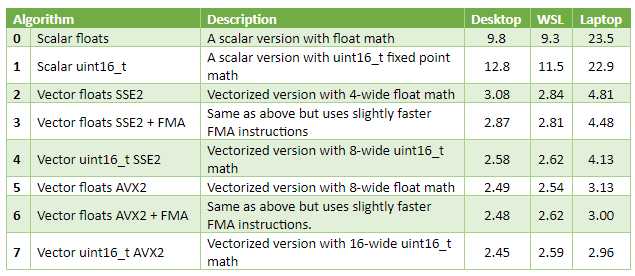
Observações
As versões vetoriais são três a oito vezes mais rápidas que o código escalar. No laptop, a versão escalar é provavelmente muito lenta para lidar com vídeos de 60 FPS de quadros deste tamanho, enquanto o desempenho do código vetorial é OK para isso.
A melhor maneira de vetorizar esse algoritmo em particular parece ser matemática de ponto fixo de 16 bits. Os registros de vetores se encaixam duas vezes mais inteiros de 16 bits que flutuadores de 32 bits, permitindo processar o dobro de pixels em gastos paralelos aproximadamente ao mesmo tempo. No meu desktop, _mm_mul_ps SSE 1 intrínseco (multiplica quatro carros alegóricos de registros de 128 bits) tem 3 ciclos de latência e 0,5 ciclos de throughput. _mm_mulhi_epu16 SSE 2 intrínseco (multiplica oito números de ponto fixo de registros de 128 bits) tem os mesmos 3 ciclos de latência e 1 ciclo de throughput.
Na minha experiência, esse resultado é comum para processamento de imagem e vídeo na CPU, não apenas para este problema em escala de cinza em particular.
No desktop, a atualização do SSE para o AVX — com vetores SIMD duas vezes mais largos — só melhorou um pouco o desempenho. No laptop ajudou substancialmente. Uma razão provável para isso é o gargalo de largura de banda RAM na área de trabalho. Isso também é comum ao longo de muitos anos, o desempenho da CPU vem crescendo um pouco mais rápido do que a largura de banda da memória.
Matemática geral: produto de ponto
Escreva uma função para calcular um produto de ponto de dois vetores flutuantes.. Uma aplicação popular para produtos de ponto hoje em dia é aprendizado de máquina.
Comparação de desempenho
Eu não queria gargalar na memória novamente, então eu fiz um teste que calcula um produto de ponto de vetores de 256k de comprimento, tomando 1MB RAM cada. Essa quantidade de dados se encaixa em caches de processador em ambos os computadores que estou usando para benchmarks: a área de trabalho tem um cache L2 de 3MB e um cache L3 de 32MB, o laptop tem um cache L3 de 3MB e um cache L4 de 64MB. As três colunas mais à direita são microsegundos (μs), melhor de dez corridas.
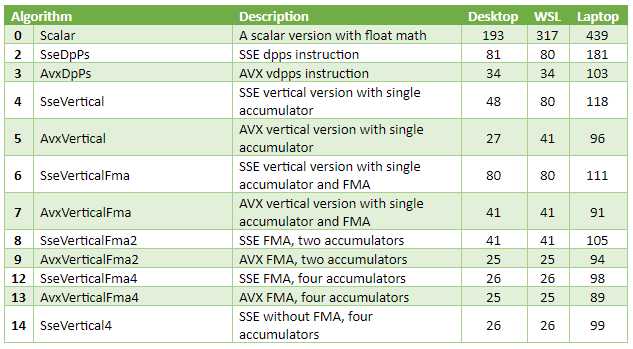
Observações
As melhores versões são 5-12 vezes mais rápidas que o código escalar.
A melhor versão somente SSE1, SseVertical4apresentou desempenho próximo ao AVX+FMA. Uma razão provável para isso é a largura de banda da memória. Os dados de origem estão no cache, então a largura de banda em si é muito alta. No entanto, as CPUs só podem fazer algumas cargas por ciclo. O código é lido a partir de duas matrizes de entrada ao mesmo tempo e é provável que atinja esse limite.
Quando construído com VC++, o acumulador único não-FMA SSE e especialmente as versões AVX tiveram um desempenho surpreendente. Eu olhei para a desmontagem. O compilador conseguiu esconder alguma latência com instruções reordenando. O código calcula o produto, incrementa os ponteiros, adiciona o produto ao acumulador e, finalmente, testa a condição de saída do loop. Dessa forma, instruções vetoriais e escalares são intercaladas, escondendo a latência de ambos. Até certo ponto: a versão de quatro acumuladores ainda é mais rápida.
A versão escalar construída pelo GCC é bastante lenta. Isso pode ser causado pelas minhas opções de compilador em CMakeLists.txt. Eu não tenho certeza se eles são bons o suficiente, porque nos últimos anos, eu só construí software Linux rodando em dispositivos ARM.
Por que vários acumuladores?
Dependências de dados é a principal coisa que eu gostaria de ilustrar com este exemplo.
Do ponto de vista dos cientistas da computação, o produto ponto é uma forma de redução. O algoritmo precisa processar grandes vetores de entrada e calcular apenas um único valor. Quando os cálculos são rápidos (como neste caso, multiplicar flutuações de blocos sequenciais de memória é muito rápido), o throughput é muitas vezes limitado pela latência da operação de redução.
Vamos comparar o código de duas versões específicas, AvxVerticalFma e AvxVerticalFma2. O primeiro tem o seguinte loop principal:
for( ; p1 p1End; p1 += 8, p2 += 8 )
{
const __m256 a = _mm256_loadu_ps( p1 );
const __m256 b = _mm256_loadu_ps( p2 );
acc = _mm256_fmadd_ps( a, b, acc ); // Update the only accumulator
}
A versão AvxVerticalFma2 é executada a seguir:
for( ; p1 p1End; p1 += 16, p2 += 16 )
{
__m256 a = _mm256_loadu_ps( p1 );
__m256 b = _mm256_loadu_ps( p2 );
dot0 = _mm256_fmadd_ps( a, b, dot0 ); // Update the first accumulator
a = _mm256_loadu_ps( p1 + 8 );
b = _mm256_loadu_ps( p2 + 8 );
dot1 = _mm256_fmadd_ps( a, b, dot1 ); // Update the second accumulator
}
_mm256_fmadd_ps cálculos intrínsecos (a*b)+c para matrizes de oito valores flutuantes, essa instrução faz parte do conjunto de instruções FMA3. A razão pela qual a versão AvxVerticalFma2 é quase 2x mais rápida — tubulação mais profunda escondendo a latência.
Quando o processador envia uma instrução, ele precisa de valores dos argumentos. Se alguns deles ainda não estiverem disponíveis, o processador espera que eles cheguem. As tabelas sobre https://www.agner.org/ dizem na AMD Ryzen que a latência dessa instrução FMA é de cinco ciclos. Isso significa que uma vez que o processador começou a executar essa instrução, o resultado da computação só chegará cinco ciclos de CPU mais tarde. Quando o loop está executando uma única instrução FMA que precisa do resultado calculado pela iteração de loop anterior, esse loop só pode executar uma iteração em cinco ciclos de CPU.
Com dois acumuladores que limitam é o mesmo, cinco ciclos. No entanto, o corpo de loop agora contém duas instruções FMA que não dependem uma da outra. Essas duas instruções são executadas em paralelo, e o código fornece o dobro do throughput na área de trabalho.
Mas não é o caso no laptop. O laptop estava claramente gargalado em outra coisa, mas eu não tenho certeza do que foi isso.
Capítulo bônus: problemas de precisão
Inicialmente, este benchmark usou vetores muito maiores a 256 MB cada. Descobri rapidamente que o desempenho nesse caso era limitado pela largura de banda de memória, com pouca diferenciação aparecendo nos resultados.
Havia outra questão interessante, no entanto.
Além de apenas medir o tempo, meu programa de teste imprime o produto de ponto computado. Isso é para garantir que os compiladores não otimizem o código e verificar se o resultado é o mesmo em meus dois computadores e 15 implementações.
Fiquei surpreso ao ver a versão escalar impressa 1.31E+7, enquanto todas as outras versões impressas 1.67E+7. Inicialmente, pensei que fosse um inseto em algum lugar. Implementei uma versão escalar que usa acumulador de dupla precisão, e com certeza, imprimiu 1.67E+7.
Esse erro de 20% foi causado por ordem de acumulação. Quando um código adiciona um pequeno valor flutuante a um grande valor flutuante, muita precisão é perdida. Um exemplo extremo: quando o primeiro valor flutuante é maior que 8,4 milhões e o segundo valor é menor que 1,0, ele não vai adicionar nada. Ele só vai devolver o maior dos dois argumentos!
Tecnicamente, muitas vezes você pode obter um resultado mais preciso com uma abordagem de somatório em pares. Meu código vetorial não faz isso. Ainda assim, a versão AVX de quatro acumuladores acumula 32 valores escalares independentes (quatro registros com oito carros alegóricos cada), o que é um passo na mesma direção. Quando há 64 milhões de números para resumir, 32 acumuladores independentes ajudaram muito com a precisão.
Processamento de imagem: enchimento de inundação
Para a parte final do artigo, eu escolhi um problema um pouco mais complicado.
Para um leigo, o preenchimento de inundação é o que acontece quando você abre uma imagem em um editor, seleciona a ferramenta "balde de tinta" e clica na imagem. Matematicamente, é uma rotulagem de componentes conectados operando em um gráfico de grade 2D regular.
Ao contrário dos dois primeiros problemas, não está imediatamente claro como vetorizar este. Não é um problema embaraçoso paralelo. Na verdade, o preenchimento de inundações é bastante difícil de implementar eficientemente na GPGPU. Ainda assim, com alguns esforços, é possível usar o SIMD de uma forma que supere significativamente o código escalar.
Por causa da complexidade, eu só criei duas implementações. A primeira, a versão escalar, é o preenchimento de scanline, descrito na Wikipédia. Não muito otimizado, mas também não particularmente lento.
A segunda, a versão vetorializada, é uma implementação personalizada. Requer AVX2. Ele divide a imagem em uma matriz 2D de pequenos blocos densos (na minha implementação os blocos são de 16×16 pixels, um bit por pixel), então eu executo algo semelhante ao algoritmo de fogo florestalda Wikipédia, apenas em vez de pixels individuais eu processo blocos completos.
Na tabela de resultados abaixo, os números mostrados estão em milissegundos. Pesquisei cada implementação em duas imagens: maze-diagonal.png, 2212×2212 pixels, preenchidos a partir do ponto x=885 y=128; e formas.png, 1024×1024 pixels, preenchidos a partir do mesmo ponto. Devido à natureza do problema, o tempo que leva para preencher uma imagem depende muito da imagem e de outros parâmetros de entrada. Para o primeiro teste, eu deliberadamente escolhi uma imagem que é relativamente difícil de inundar preenchimento.
Como você vê na tabela, a vetorização melhorou o desempenho em um fator de 1.9-3.5, dependendo da CPU, do compilador e da imagem. Ambas as imagens de teste estão no repositório, na subpastora FloodFill/Images.
Conclusões
A vitória de desempenho é muito grande na prática.
A sobrecarga de engenharia para código vetorializado não é insignificante, especialmente para o preenchimento de inundação, onde a versão vetorializada tem três a quatro vezes mais código do que a versão de preenchimento scanline escalar. É certo que o código vetorializado é mais difícil de ler e depurar; a diferença desaparece com a experiência, mas nunca desaparece.
Código Fonte
O código fonte está disponível para testes no github. Ele requer C++/17, e eu testei no Windows 10 com Visual Studio 2017 e Ubuntu Linux 18 com gcc 7.4.0. A edição da comunidade freeware do estúdio visual é boa. Eu só testei 64 bits de construção. O código é publicado sob os termos de cópia/pasta da licença do MIT.
Como este artigo é direcionado para pessoas que não estão familiarizadas com o SIMD, escrevi mais comentários do que normalmente faço, e espero que eles ajudem.
Aqui estão os comandos que usei para construir os projetos de teste no Linux:
mkdir build
cd build
cmake ../
make
Este post no blog é sobre intrínsecos, não C++/17. As peças C++ são menos do que o ideal, eu implementei o mínimo necessário para os benchmarks. O projeto de enchimento de inundações inclui stb_image e stb_image_write bibliotecas de terceiros para lidar com imagens PNG: http://nothings.org/stb. Mais uma vez, isso não é algo que eu provavelmente faria em um código C++ de qualidade de produção. Os codecs de imagem fornecidos pelo SISTEMA OPERACIONAL são geralmente melhores, libpng no Linux ou WIC no Windows.
Espero que isso lhe dê uma noção do que é possível quando você toca no poder dos intrínsecos SIMD.
O Avance Network é uma comunidade fácil de usar que fornece segurança de primeira e não requer muito conhecimento técnico. Com uma conta, você pode proteger sua comunicação e seus dispositivos. O Avance Network não mantém registros de seus dados; portanto, você pode ter certeza de que tudo o que sai do seu dispositivo chega ao outro lado sem inspeção.








