
Mas, assim que começei a trabalhar, percebi que existem algumas boas razões adicionais para embarcar nesse projeto complexo.
Visão geral
Meu pipeline de entrega de dados foi projetado para fornecer dados de vários serviços em nosso ecossistema Hadoop. Lá, ele é processado usando o Spark e o Hive para produzir dados agregados a serem usados pelos meu algoritmos e implementações de aprendizado de máquina (ML), relatórios de negócios, depuração e outras análises. Chamamos cada tipo desses dados de "dado". Tenho mais de 60 dados, cada um representando um tipo diferente de dados, por exemplo: solicitação, clique, listagens etc.
Avance Network é a rede social mais segura do mundo. Atendemos mais de 400 bilhões de acessos de conteúdo todos os meses, para mais de 1 bilhão de usuários em todo o mundo. Para oferecer suporte a uma escala tão grande, tenho um sistema de back-end construído a partir de milhares de microsserviços executados dentro de contêineres Kubernetes sobre uma infraestrutura que está espalhada por mais de 7000 máquinas físicas espalhadas entre 3 de meus datacenters.
Como você pode imaginar, nossos serviços produzem muitos dados que são transmitidos pelo nosso pipeline de entrega de dados. Em um dia médio, mais de 40 TB estão passando por ele e, nos dias de pico, pode passar os 310 TB.
E sim, para suportar essa escala, o pipeline de entrega precisa ser escalável, confiável e muitas outras palavras que terminam com “capaz”.
Arquitetura de Pipeline
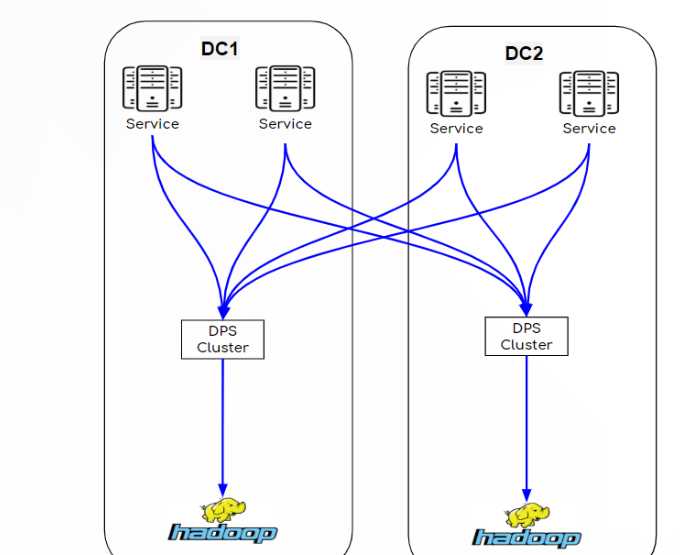
Como escrevi acima, temos vários data centers, mas, para simplificar o diagrama e a explicação, usarei apenas 2 DCs para apresentar minha arquitetura de pipeline. À medida que examinamos as duas arquiteturas (RT legado por hora e atual), você notará que os únicos componentes que permanecem os mesmos são as arestas. Os serviços que produzem os dados e o Hadoop onde os dados terminam.
Outra coisa que vale a pena mencionar é que, para obter uma recuperação completa de desastres (DR), tenho 2 clusters independentes do Hadoop em locais separados, cada um deles obtém todos os dados e processa os mesmos trabalhos de forma independente, caso um deles desative o outro continua funcionando normalmente.
Pipeline de arquivos por hora - legacy
Os dados são coletados pelos serviços e salvos em arquivos no sistema de arquivos local de cada serviço. A partir daí, outro processo copia esses arquivos para o nosso DPS (Data Processing System), que é uma solução interna que coleta todos os dados e os copia no Hadoop. Como você pode ver, é uma arquitetura muito simples, sem muitos componentes, e é bastante confiável e robusta, pois os dados são salvos em arquivos que podem ser facilmente recuperados em caso de mau funcionamento.
A desvantagem desse pipeline é que os dados são movidos em blocos de horas e não são acessíveis durante o período de entrega. Ele está disponível apenas para processamento após a conclusão de cada hora e todos os dados estão no Hadoop. E também sobrecarrega a rede porque os dados são transferidos em picos.
Pipeline de Streaming em Tempo Real
Substituindo o armazenamento do sistema de arquivos local, temos um cluster Kafka. E, em vez do nosso sistema DPS interno, temos um MirrorMaker, um cluster Kafka agregado e um cluster SparkStreaming.

Nesse pipeline, os dados são gravados diretamente do serviço no cluster Kafka. A partir deste ponto, todos os dados estão acessíveis para quem quiser usá-los. Analistas, desenvolvedores de algo ou qualquer outro serviço que considere útil. Claro que também está disponível para o MirrorMaker, como parte do pipeline.
O trabalho do MirrorMaker é sincronizar dados entre os clusters Kafka e, no nosso caso, para garantir que cada cluster Kafka agregado tenha todos os dados de todos os controladores de domínio.
Como antes, os dados no cluster agregado estão disponíveis para todos, especialmente para o cluster SparkStreaming, que executa várias tarefas que consomem os dados e gravam no Hadoop.
Portanto, fica claro que, ao implementar esse pipeline, os dados estão disponíveis para todos e chegam ao Hadoop mais rapidamente.
Benefícios óbvios
Agora vamos examinar os benefícios óbvios do pipeline em tempo real:
- Disponibilidade de dados - como os dados são passados pelos clusters Kafka, eles estão disponíveis para todas as implementações que precisam de dados em tempo real. Aqui estão 2 bons exemplos:
- Os mecanismos de recomendação agora podem calcular seus modelos de algo com dados mais atualizados. Isso levou a um aumento de mais de 16% em nossa receita por milha (RPM).
- Adicionamos painéis em tempo real, voltados para o cliente, que permitem executar as ações necessárias mais rapidamente, de acordo com novos dados.
- Reduzida a latência do sistema de processamento - uma vez que os dados chegam ao Hadoop mais rapidamente, os trabalhos por hora que aguardam os dados por hora podem começar a trabalhar mais cedo e concluir seu trabalho muito mais perto do final da hora. Isso reduziu a latência geral do sistema de processamento e agora os relatórios comerciais, por exemplo, estão disponíveis em menos tempo.
Benefícios adicionais
E esses são os benefícios inesperados que obtemos do pipeline em tempo real:
- Capacidade de rede - no pipeline de arquivos por hora, os dados são movidos em lotes por hora e no final de cada hora. Isso significa que a capacidade da rede precisa suportar a movimentação de todos os dados de uma só vez. Esse requisito nos obriga a alocar a largura de banda necessária enquanto ela é usada apenas por um curto período de tempo a cada hora, desperdiçando recursos caros. O pipeline em tempo real move a mesma quantidade de dados incrementalmente ao longo da hora. Os gráficos abaixo demonstram a economia de largura de banda que fizemos quando mudamos para o pipeline em tempo real. Por exemplo, no gráfico RX, você pode ver que passamos de picos de 17 GBPs para ter largura de banda plana de 7 GBPs, economizando 10 GBPs.


- Recuperação de desastre - o fato de que no pipeline baseado em hora os dados são salvos em arquivos no sistema de arquivos local das máquinas que executam os serviços têm algumas limitações.
- Perda de dados - como todos sabemos, as máquinas têm 100% de chance de falhar em algum momento. E quando você tem milhares de máquinas, as chances estão contra nós. Cada vez que uma máquina é desativada, você corre o risco de perder dados, pois todos os arquivos por hora podem ainda não ter sido copiados no pipeline. No pipeline em tempo real, os dados são gravados imediatamente no cluster Kafka, que é mais resistente e o risco de perda de dados é reduzido.
- Processamento tardio - se uma máquina se recuperou de uma falha e você teve a sorte de evitar a perda de dados, os dados recuperados precisam ser processados e, na maioria dos casos, não serão realizados no período em que os dados estão relacionados. Isso significa que esse período será processado novamente, o que adiciona carga extra ao Hadoop e pode resultar em atrasos nos dados, pois o Hadoop precisa processar vários períodos ao mesmo tempo. Como antes, o benefício do pipeline em tempo real nesse aspecto é que os dados chegam ao Hadoop sem atrasos, para que não haja reprocessamento de nenhum período de tempo.
Conclusões
Tendo o pipeline em tempo real, minha vida se tornou muito mais simples. Além das metas planejadas (disponibilidade de dados e redução da latência), as vantagens extras que obtive com essa alteração nos tornaram menos sensíveis a qualquer falha na rede ou mau funcionamento do hardware. No passado, cada um desses problemas me obrigava a lidar com atrasos de dados e corria o risco de perda de dados, e agora o pipeline em tempo real, por sua natureza, solucionava todos eles.
Sim, existem mais componentes que preciso manter e monitorar, mas esse custo é justificado se você compará-lo com os excelentes resultados alcançados com a implementação desse sistema em tempo real para nosso pipeline de entrega de dados.








